上次讲了线性方程组求解的迭代法,这次理所应得地就是来聊聊直接求解了。
约当消去法和高斯消去法
其实线性方程组咱们在线性代数/高等代数里都聊过的,我自己也出了专门的线性方程组求解的专利而且还重制了一版,各位观众应该是比较熟悉了的才对。(线性方程组专栏链接在这里)
这两个方法其实就是我们之前就会的,什么用初等行变换把矩阵化成行阶梯型行最简型甚至相抵标准型之类的。
就是回带的时间不一样而已,绝当消去法是直接一把梭,消元到行最简型然后直接就能观察出解了,而高斯消去法只消到行阶梯型然后回代解一元一次方程。
所以这两个方法我觉得无需多言(啊,看见这四个字又想玩梗了)。
本文的重点在于利用矩阵分解来求解方程组。
LU分解
这一切的基石来源于LU分解。
不过在这里我要澄清一个观念。
在线性代数/高等代数里我们强调过,矩阵乘法的几何意义是矩阵对应的线性变换的乘法(也就是复合),所以在这种意义上,所谓的矩阵分解应该是把一个矩阵分解成若干个矩阵的乘积。
而在上文中,我曾经说把一个矩阵A分解为上三角U、下三角L、对角阵D使得A=D-L-U,这不是我们这里说的矩阵分解。这里所谓的分解只是从代数的角度或者说凑数的角度看把一个矩阵拆分成三个矩阵的和,是没有几何意义的。
好,我们现在澄清完了可以开始LU分解的内容了。
LU分解也是一种直接求解的方法,他是这样想的。
我们对AX=b的系数矩阵A进行预处理,把他分解成下三角矩阵L和上三角矩阵U的乘积。
即找一个下三角矩阵L和上三角矩阵U使得A=LU
然后AX=b就是LUX=b,也就是L(UX)=b。
为什么要这么做呢?
因为这样我们可以换元,令y=UX
则Ly=b是轻易求解的,UX=y也是轻易求解的。
例如
$ A=\begin{pmatrix} 1 & 2 & 3 \ 2 & 5 & 2 \ 3 & 1 & 5 \end{pmatrix},b=\begin{pmatrix} 14 \ 18 \ 20 \end{pmatrix} $
我们可以进行LU分解
$ A=\begin{pmatrix} 1 & 2 & 3 \ 2 & 5 & 2 \ 3 & 1 & 5 \end{pmatrix}=\begin{pmatrix} 1 & 0 & 0 \ 2 & 1 & 0 \ 3 & -5 & 1 \end{pmatrix}\begin{pmatrix} 1 & 2 & 3 \ 0 & 1 & -4 \ 0 & 0 & 24 \end{pmatrix}$
显然前面那个矩阵就是L,后面那个是U。
我们先解Ly=b,从上往下看第一个方程$y_1=14$直接解出来了。
第二个方程$2y_1+y_2=18$,很容易解出$y_2=-10$。
然后是第三个方程$3y_1-5y_2+y_3=20$,解出$y_3=-72$。
果然容易求解吧。
然后求解UX=y
也就是
$\begin{pmatrix} 1 & 2 & 3 \ 0 & 1 & -4 \ 0 & 0 & 24 \end{pmatrix}X=\begin{pmatrix} 14 \ -10 \ -72 \end{pmatrix}$
从下往上看,第一个方程$24x_3=-72,x_3=3$,
第二个方程$x_2-4x_3=-10,x_2=2$,
第三方程$x_1+2x_2+3x_3=14,x_1=1$。
现在就很轻易地解出了方程。
但是问题来了,怎么进行LU分解呢?
我们以分解$A=\begin{pmatrix} 4 & 2 & -2 \ 2 & 2 & -2 \ -2 & -3 & 13 \end{pmatrix}$为例,先进行初等行变换。
但是这里我们只能做把某一行的k倍加到另一行,从而把A化成上三角矩阵。
$A=\begin{pmatrix} 4 & 2 & -2 \ 2 & 2 & -2 \ -2 & -3 & 13 \end{pmatrix}$
首先,第一行的一半加到第三行,然后第一行的-0.5倍加到第二行,然后你给4 2 -2这三个元素画圈。
你会首先得到矩阵
$\begin{pmatrix} 4 & 2 & -2 \ 0 & 1 & -1 \ 0 & -2 & 12 \end{pmatrix}$
然后再把第二行的2倍加到第三行,给1 -2画圈。
得到
$\begin{pmatrix} 4 & 2 & -2 \ 0 & 1 & -1 \ 0 & 0 & 10 \end{pmatrix}$
这个就是U了,当然最后记得给10画圈。
那L呢?
我们只做了初等行变换对吧,我们知道给矩阵做初等行变换等价于在左边左乘一系列初等矩阵,L就是这些初等矩阵的乘积。
为了保证这些初等矩阵的乘积是下三角矩阵所以我们才要求你只能做把某一行的k倍加到另一行这一种变换。
那么这个L要不要自己手动去整理一下找到我们乘了哪些初等矩阵然后再计算乘积呢?不用这么麻烦。
前面不是让你画圈了吗?
你把画圈的元素拼起来,得到
$\begin{pmatrix} 4 & 0 & 0 \ 2 & 1 & 0 \ -2 & -2 & 10 \end{pmatrix}$
这个矩阵,还不是L啊哈哈。
我们得到的L比这个还要强其实。
我们的L是一个单位下三角!
你要做的是,每一列乘以某个数把他变成单位下三角,也就是第一列除以4,第二列除以1,第三列除以10得到
$\begin{pmatrix} 1 & 0 & 0 \ \frac{1}{2} & 1 & 0 \ -\frac{1}{2} & -2 & 1 \end{pmatrix}$
这个才是L。
我们这里分解出来的L是单位下三角,其实你也可以分解出单位上三角。
换言之,LU分解是不唯一的。你也可以分解成两个普通的上下三角矩阵。
所以为了保证分解的唯一性,我们会要求L或者U的其中一个是单位上下三角。
如果L是单位下三角这样的分解叫Doolittle分解,U是单位上三角则这样的分解是Crout分解。
Choloesky分解
除了LU分解之外还有办法。
不过我们得给矩阵A加一些条件了。我们要求A是正定阵。
如果A是正定矩阵我们会得到特殊的结论。
先对A进行一次LU分解,A=LU’,接着如果我们对U’再次进行LU分解,你会得到$U’=DL^T$。
所以正定矩阵A可以分解为$LDL^T$。
这个就是Choloesky分解。
其中D很特殊,D是一个对角阵,也就是说$U’$的LU分解分解出的下三角矩阵是一个对角阵而L是单位下三角矩阵。
所以你应该意识到,两次LU分解进行的是不同的LU分解,第一次把L分解为单位下三角,也就是进行Doolittle分解,此时U‘是一般的上三角矩阵。
然后对U’进行Crout分解,把分解出来的上三角化为单位上三角并且这个单位上三角刚好是$L^T$,此时下三角矩阵刚好是对角阵。
所以如果是正定矩阵,你可以对A先进行一次LU分解,得到L,那么他的Choloesky分解里就只有对角阵D不知道了。
而对角阵D其实也是很容易就知道的。
因为U’你是知道的,而$U’=DL^T$,我们可以用这个关系得到D。
例如$A=\begin{pmatrix} 3 & 2 & 3 \ 2 & 2 & 0 \ 3 & 0 & 12 \end{pmatrix}$
进行一次LU分解得到
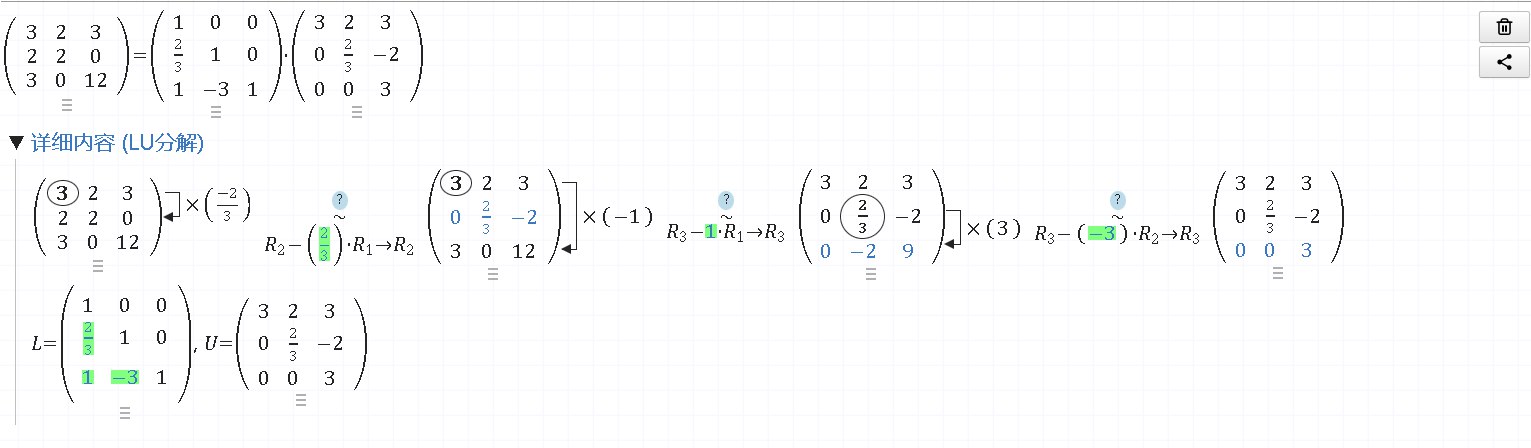
哦对了,这个是这个网站计算得到的。(网址https://matrixcalc.org/zh-CN/)
然后我们知道L和U’了
由于U’=DL,你可以先用待定系数法求D。
自己试试看,然后你就会发现好像不用那么麻烦了。
因为
$U’=\begin{pmatrix} d_{11} & 0 & 0 \ 0 & d_{22} & 0 \ 0 & 0 & d_{33} \end{pmatrix}\begin{pmatrix} 1 & \frac{2}{3} & 1 \ 0 & 1 & -3 \ 0 & 0 & 1 \end{pmatrix}$
我们只算U’的对角元。
第一行乘第一列,就是$d_{11}$
第二行乘以第二列就是$d_{22}$
第三行乘以第三列就是$d_{33}$
所以D的对角元是啥?不就是U‘的对角元?所以D也可以直接看出来。
平方根法(平方分解)
由Cholesky分解还可以进一步得到平方分解。
对于正定矩阵A它可以分解为$LDL^T$
但是D也可以进一步拆分啊。
再构造一个对角阵$D’=diag(\sqrt{d_{11}},\sqrt{d_{22}},…,\sqrt{d_{nn}})$
那么D就可以看作是$D’D’^T$
所以$A=LDL^T=LD’D’^TL^T=(LD’)(LD’)^T$
如果我设$L’=LD’$则$A=L’L’^T$
此时我们说$L’=\sqrt A$
这就是A的平方根分解。
只不过,相比于上一种方法这个方法其实计算量更大。
这个叫平方根法,前面那种方法我们叫改进平方根法。
啊哈哈,这次反而是先推出改进版的方法。
不过其实平方根分解还可以由谱分解导出。
如果矩阵A可正交相似对角化,那么就存在一个正交矩阵P和对角阵D,使得$A=PDP^{-1}$
我们知道,P矩阵实际上就是A的各正交特征向量$e_{i}$,D矩阵的对角元就是A的特征值$\lambda_{i}$。
但是,这个式子稍加变化就可以直接得出A的平方根分解了。
我们设$\Lambda=diag(\sqrt{\lambda_1},\sqrt{\lambda_2},…,\sqrt{\lambda_n})$,
那么就有$D=\Lambda\Lambda=\Lambda\Lambda^{T}$,实际上我们在这里顺便对对角矩阵D进行了平方根分解。
但是把D的平方根分解代入得$A=P\Lambda\Lambda P^{-1}$
我们知道P是正交阵,所以$P^{-1}=P^{T}$。
从而$A=P\Lambda \Lambda^{T}P^{T}=P\Lambda(P\Lambda)^T$
所以所以,$P\Lambda$就是A的平方根。
如果我们将$P\Lambda$写开就是$(e_1\sqrt{\lambda_1},e_2\sqrt{\lambda_2},…,e_n\sqrt{\lambda_n})$
之后你将多次看到这个矩阵,实际上是我们用谱分解进行了一次平方根分解。
追赶法
之前我们就说过,三对角矩阵可以用追赶法来求解。
现在重要可以来唠唠追赶法了。
追赶法其实就是对三对角矩阵的LU分解。
但是三对角矩阵的LU分解也是特殊的。
例如计算
$A=\begin{pmatrix} 2 & -1 \ -1 & 2 & -1 \ & -1 & 2 &-1 \& & -1 &2 &-1\& & & -1 &2 \end{pmatrix}$
它的L一定是这样的形式
$L=\begin{pmatrix} \alpha_1 & \ -1 & \alpha_2 \ & -1 & \alpha_3 \& & -1 &\alpha_4 \& & & -1 &\alpha_5 \end{pmatrix}$
其中最下面那排-1啊,是和A的最下面那排一样的。
A的U啊,是单位上三角
$U=\begin{pmatrix} 1 & \beta_1 \ & 1 & \beta_2 \ & & 1 &\beta_3 \& & &1 &\beta_4\& & & &1 \end{pmatrix}$
那么关键就是证明求$\alpha_i$和$\beta_i$了呗。
方法是直接把LU相乘,毕竟LU=A嘛
L的第一行乘以U第一列得到$\alpha_1=2$
然后我们再算$\beta_1$
也就是L的第一行乘以U的第二列,得到$\beta_1$
然后我们算$\alpha_2$
用L的第二行乘以U的第二列。
以此类推。
你会发现我们是先算$\alpha_i$再算$\beta_i$
所以形象的说就是有个追赶的过程。
因此这个方法的名字叫追赶法。
至于你说,我不想用矩阵乘法这么麻烦来算,其实这玩意儿有公式,但是我个人觉得反而更麻烦了,而且公式很难记忆,想知道的话还是自己上网查吧。
最后呢,矩阵分解的气氛都烘托到这里了,再多聊了五毛钱的。
奇异值分解
矩阵分解里有两个非常重要的分解,其中一个是谱分解,这个在所有线性代数/高等代数课堂上都会介绍,但是奇异值分解却鲜有说明的。
我们知道,矩阵的几何意义是线性变换,而线性变换其实只有两种。
一种是伸缩变换,他只改变向量的长度,也就是只伸缩。
另一种是正交变换,也就是旋转,它不改变向量的长度以及几何图形的形状。
而奇异值分解做的事情是,把一个一般的线性变换A分解成伸缩变换+旋转变换。
我们知道,旋转变换的矩阵是正交阵Q(对复数域的矩阵,旋转变换的矩阵是正规阵),而伸缩变换的矩阵是对角阵D。
由于线性代数课程不介绍复数域矩阵,在此对正规矩阵进行说明。
对于实数域的矩阵有一个操作叫转置,所谓A的转置$A^T$,就是把A的第i行变到第i列。
而在复数域的矩阵,和转置对等的叫共轭转置$A^H$,他首先把A中的所有元素取共轭复数,然后再进行转置。
由于实数的共轭复数是实数本身,所以对实矩阵的转置其实也可以看做是共轭转置。
而在实数域上,我们说如果一个矩阵满足$A=A^T$,就说A是对称矩阵。
在复数域上就变成了,如果$A=A^H$则称A是艾尔米特(Hermitian)矩阵。
在实数域上,正交阵指的是$A^T=A^{-1}$,
而在复数域上我们说正规矩阵指的是$A^H=A^{-1}$
也就是说我们希望把一个矩阵A分解成QD。
但是这是做不到的。
实际上我们能做的是这样的。
把A对应的线性变换分解为:
我先进行一次旋转,然后再进行伸缩,最后再旋转回去。
也就是说,我们要找两个正交矩阵P、Q,一个对角矩阵D,使得
$A=PDQ^T$
这就是奇异值分解了。
当然,这件事在复数域上就变成了找两个正规矩阵P、Q,一个对角阵D,使得$A=PDQ^T$。
他有很多用途,例如进行低秩估计等,不过与本文无关了。
注意,奇异值分解并不要求A是一个方阵,他也不用可逆啊什么的,我们对A没有任何要求。
那么问题来了,如何对A进行奇异值分解?
非常简单。
观察式子$A=PDQ^T$
对A进行转置$A^T=QDP^T$
然后算一下$AA^T$和$A^TA$看看
$AA^T=PD(Q^TQ)DP^T=PDDP^T=PD^2P^T$
$A^TA=QD(P^TP)DQ^T=QDDQ^T=QD^2Q^T$
由于D是对角阵所以D²也是对角阵,因此上面两个等式不就是对$AA^T,A^TA$进行正交相似对角化吗?
也因此$D^2$就是$AA^T,A^TA$的特征值拼成的对角阵。
一般地,我们对对角矩阵D的元素是有名字的,而且还有顺序要求。(虽然数学上没有这个限制,但是我们实际计算的时候为了保证D的唯一性所以要求D的元素要从小到大排)
我们称D的最大的元素为A的第一奇异值$\sigma_1$,D第二大的元素为第二奇异值$\sigma_2$,以此类推。
这样的话,A的第i奇异值$\sigma_i$就是$AA^T,A^TA$的第i大特征值的平方根了。
但是你可能又注意到了,一个数的平方根有两个啊,所以我们为了保证唯一性还会要求各奇异值>0,也就是大家都取算术平方根。
所以最后的最后,A的第i奇异值$\sigma_i$就是$AA^T,A^TA$的第i大特征值的算术平方根了。
而再观察前面的式子P和Q就是$AA^T,A^TA$的特征向量拼成的矩阵,也可以跟着求得。
我们来试试看,对
$A=\begin{pmatrix} 1 & 2 \ 2 & 0 \ 0 & 2 \end{pmatrix}$进行奇异值分解。
首先计算$A^TA$的特征值特征向量,得到特征值为9,4
所以A的第一奇异值是3,第二奇异值是2。
因此对角阵$D=\begin{pmatrix} 3 & 0 \ 0 & 2 \ 0 & 0 \end{pmatrix}$
嗯,你会发现,由于A不是方阵,所以D也不是方阵,所以D其实不是对角阵,但是他的第i行第i列还是填的第i奇异值。
如果你发现最后奇异值不够用了,少了,那么你就在矩阵里补0就可以了。
至于P和Q,我们可以用$A^TA$的特征向量拼出$Q=\begin{pmatrix} \frac{1}{\sqrt 5} & \frac{2}{\sqrt 5} \ \frac{2}{\sqrt 5} & \frac{-1}{\sqrt 5} \end{pmatrix}$
那P呢,你也可以对$AA^T$继续求特征向量啦,但其实没有必要。
你看哈,$A=PDQ^T$,我们两边右乘Q就有$AQ=PD$,从而就有$Aq_i=\sigma_ip_i$,其中$p_i,q_i$是P和Q的特征向量。
式子里AQD都是已知的,我们就可以直接求出$q_i$了。
(其实,要求P,直接$P=AQD^{-1}$就可以了,也用不着这个什么性质,但我这边特绕远就是为了说奇异值有这个性质而已)
类似地,我们还能求出$A^Tp_i=\sigma_i q_i$。
奇异值分解在这个系列里的用途主要是,可以用奇异值求矩阵的2-范数。
赋范空间
我们已经不止一次提到,满足下面八大条的非空集合就是线性空间
设V是一个非空集合,P是一个域(不只是数域)。若:
1.在V中定义了一种运算,称为加法,即对V中任意两个元素α与β都按某一法则对应于V内惟一确定的一个元素α+β,称为α与β的和。
2.在P与V的元素间定义了一种运算,称为纯量乘法(亦称数量乘法),即对V中任意元素α和P中任意元素k,都按某一法则对应V内惟一确定的一个元素kα,称为k与α的积。
3.加法与纯量乘法满足以下条件:
- α+β=β+α,对任意α,β∈V.
- α+(β+γ)=(α+β)+γ,对任意α,β,γ∈V.
- 存在一个元素0∈V,对一切α∈V有α+0=α,元素0称为V的零元.
- 对任一α∈V,都存在β∈V使α+β=0,β称为α的负元素,记为-α.
- 对P中单位元1,有1α=α(α∈V).
- 对任意k,l∈P,α∈V有(kl)α=k(lα).
- 对任意k,l∈P,α∈V有(k+l)α=kα+lα.
- 对任意k∈P,α,β∈V有k(α+β)=kα+kβ,
我们可以给线性空间增加内积结构把他变成内积空间(也叫欧几里得空间)。
在这里,我们要给他增加距离结构,或者叫范数。
所谓范数就是长度的推广,所以我们要求范数满足长度的基本性质。并且要明确,范数的结果是数,所以范数是线性空间内的向量到数的一元映射。
设V是数域P上的抽象的线性空间,我们在V上定义V到数域P的映射$| .|$,如果他满足下面三个长度应该满足的基本性质
1.非负性:即V上任意抽象的向量的范数都大于等于0,并且只有零向量的范数为0。
2.齐次性:即对于V上的任意抽象的向量x,P上的任意数k,有$|kx|=|k||x|$,也就是常数k可以提出来。
3.三角不等式:即两边之和大于第三边,也就是对于V上的任意抽象的向量x,y,都有$|x+y|\le|x|+|y|$。
那么我们就称映射$| .|$是抽象的线性空间V上的范数,此时我们称V加上范数组成的代数结构为赋范线性空间。
以前我们用抽象向量的内积定义过距离,这其实也就意味着由内积空间可以诱导出赋范空间,但是反过来是不行的。也就是我们不能由范数得到内积。
在这里,线性空间、内积空间、赋范空间都是抽象的,我们并没有指明所谓是向量一定是高中学的那种n维向量,它完全可以是矩阵、可以是函数、也可以是别的什么东西。
那我们取一些特例。
向量范数
对于n维向量$x=(x_1,x_2,x_3,…,x_n)$,有一类特殊的范数称为p-范数。
他是$|x|_p=^\sqrt[p]{x_1^p+x_2^p+…+x_n^p}$。
当p=1时,1-范数就是各分量绝对值的和。
当p=2时,就是我们熟知的现实生活中的距离。
更特殊的是p=+∞的时候,无穷范数实际上是x的最大分量的绝对值。
当然,虽然范数有很多,但是p-范数之间是等价的。
也就是说,你搞一个n维向量的点列$x_n$,只要$x_n$的任意一个范数趋于$x_0$,那么$x_n$的其他范数也是趋于$x_0$的。
矩阵范数
n维向量有范数,而我们知道,mxn的矩阵全体也是一个抽象线性空间,所以它也能定义范数。
一个简单的想法是继续沿用向量p-范数的定义,例如我们定义一个矩阵的范数是各个元素的平方和再开根号。
这当然是可以的,只要我们定义的范数满足三个长度的基本性质就可以了。
其实我刚刚随口胡诌的范数是矩阵的F-范数。
一个更常见的矩阵范数是由刚刚说的向量的p-范数诱导出来的。
所以这种范数被称为诱导范数,也称为矩阵的p-范数。
他是这么想的,$A$是一个矩阵,但是矩阵乘以向量就得到向量了啊,我们可以用$Ax$的范数定义A的函数。
但是取什么样的x呢?
答案是取单位向量x,但是单位向量又有无穷多个,又该取哪个呢?
这里啊,诱导范数选择的是取$Ax$最大的那个。
所以最终矩阵的p-范数定义是,
$|A|_p=\max |Ax|_p$
其中x是单位向量,也就是x的p-范数为1。
但是你在其他地方看到的矩阵范数可能不长这样,他们没有要求x是单位向量而是在范数的结果上除以了x的范数,这是等价的。
矩阵p-范数的等价定义是
$|A|_p=\max \frac{|Ax|_p}{|x|_p}$
但是我们必然是不会傻乎乎地用定义去算矩阵范数的。
而是选择直接预制公式。
例如矩阵的2-范数其实是A的第一奇异值。
比如$A=\begin{pmatrix} 2 & 1 \ -2 & 1 \end{pmatrix}$
我们求$A^TA=\begin{pmatrix} 8 & 0 \ 0 & 2 \end{pmatrix}$
的最大特征值,再开根号就得到了A的第一奇异值,也是A的2-范数。
下面给予证明。
$|A|_2=\max \frac{|Ax|_2}{|x|_2}$
而右边分子分母都是向量的2-范数。
我们知道n维向量$x=(x_1,x_2,x_3,…,x_n)$的2-范数是$\sqrt{(x_1^2+x_2^2+…+x_n^2)}$,这也可以表示为$\sqrt{x^Tx}$。
从而就有
$|A|_2=\max \frac{|Ax|_2}{|x|_2}=\max \sqrt{\frac{x^TA^TAx}{x^Tx}}$
这里已经出现了熟悉的$A^TA$了。
我们对$A^TA$进行正交相似对角化,即找一个单位正交矩阵P和对角阵D使得$A^TA=P^{T}DP$
代入得
$|A|_2=\max \frac{|Ax|_2}{|x|_2}=\max\sqrt{\frac{x^TP^TD(Px)}{x^Tx}}=\max\sqrt{\frac{(Px)^TD(Px)}{x^Tx}}$
由于P是正交矩阵,所以$PP^T=E$
那我就在分母动点手脚。
$|A|_2=\max\sqrt{\frac{(Px)^TD(Px)}{x^Tx}}=\max\sqrt{\frac{(Px)^TD(Px)}{x^TP^TPx}}=\max\sqrt{\frac{(Px)^TD(Px)}{(Px)^T(Px)}}$
现在进行换元,令$y=Px$
则
$|A|_2=\max\sqrt{\frac{y^TDy}{y^Ty}}$
分子分母其实都是关于y的二次型,或者说我们把矩阵乘法展开
$|A|_2=\max\sqrt{\frac{y^TDy}{y^Ty}}=\max\sqrt{\frac{\lambda_1y_1^2+\lambda_2y_2+…+\lambda_ny_n^2}{y_1^2+y_2^2+…+y_n^2}}$
然后进行放缩。
我们先给$A^TA$的特征值,也就是A的奇异值进行排序,认为$\lambda_1\ge\lambda_2\ge…\ge\lambda_n$
现在我把所有的$\lambda_i$都放大为$\lambda_1$。
就有:
$|A|_2=\max\sqrt{\frac{\lambda_1y_1^2+\lambda_2y_2+…+\lambda_ny_n^2}{y_1^2+y_2^2+…+y_n^2}}\le \sqrt{\lambda_1\frac{y_1^2+y_2^2+…+y_n^2}{y_1^2+y_2^2+…+y_n^2}}=\sqrt{\lambda_1}$
现在只要证明
$\sqrt{\frac{y^TDy}{y^Ty}}$能取到$\lambda_1$就可以了,这是显然的,我们取$y=(1,0,0,0,0,…,0)$就可以了。
所以最终结论,A的2-范数就是A的第一奇异值。
矩阵的1范数和无穷范数就比较简单了。
我举个例子秒会算。
$A=\begin{pmatrix} 2 & 1 \ -2 & 1 \end{pmatrix}$
要算1-范数,就先算每一列元素的绝对值的和即4,2
然后取最大的那个。
无穷范数就是计算每一行元素的绝对值的和即3,3
然后取最大的那个3。
也因为1-范数是先算列元素,所以他也叫列范数,无穷范数则叫行范数。
这里比较容易把行和列搞反,但是你得知道1是竖着写的,竖着的是列啊!∞是横着写的,横着是行。
我们以1-范数为例证明一下。
我们把$Ax$写成$\begin{pmatrix} a_1, & a_2, & …&a_n \end{pmatrix}\begin{pmatrix} x_1 \ x_2 \…\x_n \end{pmatrix}=a_1x_1+a_2x_2+…+a_nx_n$
然后取范数就有
$|Ax|1=|a_1x_1+a_2x_2+…+a_nx_n|{1}$
再运用三角不等式,
$|Ax|1=|a_1x_1+a_2x_2+…+a_nx_n|{1}\le|x_1||a_1|_1+|x_2||a_2|_1+…+|x_n||a_n|_1$
然后我们再把$a_i$放大为最大的那个$a_k$
$|Ax|1=|a_1x_1+a_2x_2+…+a_nx_n|{1}\le|x_1||a_1|_1+|x_2||a_2|_1+…+|x_n||a_n|_1\le(|x_1|+|x_2|+…+|x_n|)|a_k|_1$
式子左边的括号就是x的1-范数,所以
$|Ax|_1\le|x|_1|a_k|_1$
而$|A|_1=\max \frac{|Ax|_1}{|x|_1}\le\frac{|x|_1|a_k|_1}{|x|_1}=|a_k|_1$
也就是说A的1-范数小于等于第k列的1-范数,而$a_k$是一个向量,他的1-范数就是各分量绝对值的和,所以$|a_k|_1$就是第k列元素绝对值的和。
现在只需要说明$|a_k|_1$是能取到的就可以了,这个非常简单,只需取$x_k=1$,其他都为0即可。
无穷范数是类似的,差个转置而已,就不浪费时间说明了。