上一期咱们介绍了多维随机变量的矩估计和极大似然估计以及他们的R语言实现。这一期理所应当的要介绍多元正态分布的假设检验。
假设检验其实是能检验很多的,但是最经典的是对均值向量和方差的检验。而他们的检验全部依赖于统计距离。
统计距离
我们知道多维随机变量实际上是一个向量,而向量我们是有长度/范数/模的概念的。
在统计学里,我们常见的所谓距离被称为欧几里得距离,简称欧氏距离。
也就是,对两个列向量X,Y,他们之间的欧几里得距离定义为$d(X,Y)=\sqrt{(X-Y)^T(X-Y)}$,也就是X-Y的2-范数。
这个欧氏距离就是我们现实中两点的距离,但是他在统计学中没有那么好用。
这是因为欧氏距离没有考虑到数据本身的变化尺度不同,也没有考虑到变量之间的相关性,更没有克服量纲的影响。
比如说随机变量只在(-1千克(kg),1kg)变化,那原来-1kg到1kg距离差是2kg,在欧氏距离下就是2。
可是我现在如果用克(g)做单位,那-1kg到1kg的距离差就变成2000了,这显然是不合理的,甚至可以说是不可理喻的。
即便有的时候不同维度的数据你使用同一个单位,但是数据本身的变异性是有差距的。例如你计算马拉松成绩和100米成绩,显然马拉松成绩的秒数远远大于一百米成绩的秒数,这时候直接用数据之间的欧氏距离也是不合理的。
也因此,我们在统计学中会使用由马哈拉诺比斯提出的马氏距离。
其实说起来也非常简单,你不是要克服量纲的影响吗?
给随机变量标准化一下不就行了?
例如,两个随机变量X,Y,我们都进行标准化(也就是左乘协方差的根号的逆矩阵),然后再计算他们的欧氏距离。
这里先说明一下,在一元情况下,方差D(X)是标准差$\sigma$的平方也就是$\sigma^2$,而现在我们已知的是方差,因此标准差$\sigma=\sqrt{D(X)}$。
但是对于多元情况,D(X)是一个矩阵,但是你给矩阵开根号是什么意思呢?
我们在上一个系列——数值计算方法中提过矩阵的平方根分解:
由Cholesky分解还可以进一步得到平方分解。
对于正定矩阵A它可以分解为$LDL^T$
但是D也可以进一步拆分啊。
再构造一个对角阵$D’=diag(\sqrt{d_{11}},\sqrt{d_{22}},…,\sqrt{d_{nn}})$
那么D就可以看作是$D’D’^T$
所以$A=LDL^T=LD’D’^TL^T=(LD’)(LD’)^T$
如果我设$L’=LD’$则$A=L’L’^T$
此时我们说$L’=\sqrt A$
这就是A的平方根分解。
我们这里指的就是这样的矩阵开根号。
好了,现在来计算一下马氏距离的计算公式。
因为要先进行标准化,所以先得到X,Y的协方差矩阵$\Sigma$。
然后我们来计算马氏距离的平方$D^2(X,Y)=|\sqrt{\Sigma}^{-1}X-\sqrt{\Sigma}^{-1}Y|_2^2=(\sqrt{\Sigma}^{-1}X-\sqrt{\Sigma}^{-1}Y)^T(\sqrt{\Sigma}^{-1}X-\sqrt{\Sigma}^{-1}Y)$
所以$D^2(X,Y)=(X-Y)^T(\sqrt{\Sigma}^{-1})^T\sqrt{\Sigma}^{-1}(X-Y)$
别忘了$\Sigma$是对称矩阵哦。
因此$D^2(X,Y)=(X-Y)^T\Sigma^{-1}(X-Y)$
所以$D(X,Y)=\sqrt{(X-Y)^T\Sigma^{-1}(X-Y)}$
这就是马氏距离的计算公式了。而当X,Y的协方差矩阵为单位阵I的时候,马氏距离就退化为了欧氏距离。
方差已知情形的均值检验
在一元情况,针对标题说的这种方差已知的均值检验我们用的是z检验法。
也就是$H_0:\mu=\mu_0,H_1:\mu\neq\mu_0$,方差$\sigma^2$已知时,寻找枢轴统计量
$$Z=\frac{\mu-\mu_0}{\sqrt{\frac{\sigma^2}{n}}}$$利用该枢轴变量服从标准正态分布来进行检验。
你睁大眼睛看看,Z不就是$\mu$和$\mu_0$的马氏距离吗?
可以想象,如果$\mu=\mu_0$,那么样本的均值应该和他声称的均值的距离很小才对,这就是方差已知情况的均值检验的原理。
现在针对多元情况我们仍然是这么做的。
检验枢轴统计量$\overline X$与$\mu_0$的马氏距离的平方是否很小。
即检验$T^2=n(\overline X-\mu_0)^T\Sigma^{-1}(\overline X-\mu_0)$是否很小。
需要注意的是,前面我们说过,均值$\overline X$服从的是均值为$\mu$,方差为$\frac{\Sigma}{n}$的正态分布,所以在上面是式子里,那个分子上的n其实是从$\overline X-\mu_0$的方差的分母上翻上去的。
但是,这个统计量服从什么分布呢?
这个分布由霍特林和许宝禄分别由不同方法导出,不过现在国际上还是叫霍特林T²分布。
一般地,如果X服从$N_p(\mu,\Sigma)$,S服从$W_p(n,\Sigma)$且X与S独立而且n≥p,则统计量$T^2=nX^TS^{-1}X$服从非中心的霍特林$T^2$分布,记作$T^2(p,n,\mu)$。当$\mu=0$时,称为中心霍特林T²分布,记作$T^2(p,n)$。
显然,这个定义和我们推导的式子可以说是一一对应,从而我们知道刚刚找到枢轴统计量服从$T^2(p,n-1)$分布。
并且这个T²分布就是一维情况下t分布的推广。
除此之外,$T^2(p,n)$还可以转化为F分布,这是因为统计量$\frac{n-p+1}{np}T^2$服从$F(p,n-p+1)$分布。
从而,协方差已知情况下,均值向量检验也可以用刚刚的定理转化为F检验。
只需要构造枢轴统计量$\frac{(n-1)-p+1}{(n-1)p}T^2=\frac{(n-1)-p+1}{(n-1)p}n(\overline X-\mu_0)^T\Sigma^{-1}(\overline X-\mu_0)$,他就服从F(p,n-p)了。
但是实际上我们用的最多的都不是前面说的两者。
这是因为,你仔细看看,$T^2=n(\overline X-\mu_0)^T\Sigma^{-1}(\overline X-\mu_0)$这是二次型啊,它是服从自由度为p的卡方分布的啊。
所以我们最常用的其实是卡方检验。
方差未知的均值检验
那如果是方差未知的均值检验,我们又该怎么做呢?
其实答案非常显而易见,就是用样本的协方差S估计随机变量的方差。
例如我们使用霍特林T²检验就构造统计量
$T^2=n(\overline X-\mu_0)^TS^{-1}(\overline X-\mu_0)$他就服从$T^2(p,n-1)$了。
同样地,我们还是可以把他转成F分布,只需要构造枢轴统计量$\frac{(n-1)-p+1}{(n-1)p}T^2=\frac{(n-1)-p+1}{(n-1)p}n(\overline X-\mu_0)^TS^{-1}(\overline X-\mu_0)$,他就服从F(p,n-p)了。
两样本的均值检验
如果是两样本的均值检验,我们是要按有没有共同已知的协方差阵分情况讨论的。
待检验的原假设$H_0:\mu_1-\mu_2=0$,备择假设$H_1:\mu_1-\mu_2\neq0$
我已经特意写成了单样本的情况,显然这里只需要检验$\overline X_1-\overline X_2$与均值0的关系就可以了,这是一个单样本的均值检验。
不过需要注意的是$X=\overline X_1-\overline X_2$的方差是$\overline X_1,\overline X_2$方差的和。
现在直接将方差代入单样本的霍特林T²检验,形式上你就会得到$T^2=\frac{(\overline X_1-\overline X_2)^T(\overline X_1-\overline X_2)}{\frac{\Sigma}{n_1}+\frac{\Sigma}{n_2}}$
但我们知道,矩阵怎么会有除法呢?所以要整理一下变成真正的矩阵运算的样子,
构造$T^2=\frac{n_1n_2}{n_1+n_2}(\overline X_1-\overline X_2)^T\Sigma^{-1}(\overline X_1-\overline X_2)$
当然,他也服从霍特林T²分布,也服从自由度为p的卡方分布,也可以转化为F分布。
如果是有共同未知的协方差矩阵的两样本,那和一元情况一样我们用$S_{pl}=\frac{(n_1-1)S_1+(n_2-1)S_2}{n_1+n_2-2}$替代随机变量的方差即可。
至于其他情形,要么推导和前面的方法一致要么就过于复杂,在此不再介绍。
最后提一下,我们在以前学习一元检验的时候就知道,单因素方差分析其实就是多正态总体的均值向量检验。
而在多元情况下,我们需要使用威尔克斯分布才行。
如果X服从$W_p(n_1,\Sigma),n_1\ge p$,Y服从$W_p(n_2,\Sigma),\Sigma\gt0$,且X,Y独立,则$\Lambda=\frac{|X|}{|X+Y|}$服从威尔克斯分布,记作$\Lambda(p,n_1,n_2)$。
如果要把威尔克斯分布转为F分布,需要先转为霍特林T²分布再转为F分布,至于这么转。。。
也比较复杂,需要一张关系表才能表示清楚,反正不是随随便便哪个人能碰的啊哈哈。(彻底陷入疯癫)
除此之外,巴特莱特(Bartlett)还提出了用卡方分布来近似威尔克斯分布的办法,Rao则研究出了用F分布近似的办法。但都挺麻烦的。。。
至于你要对多元情况进行方差分析,你得构造似然比统计量,这个已经远远超出大部分人的能力了,还是散了吧。
协方差阵的检验的话,单正态总体就比较复杂了,构造的检验统计量里既要算e指数,又要搞什么矩阵开方,搞什么行列式云云的,完事最后还只能用极限分布是卡方分布来算,反正也麻烦得要死。。。
多样本协方差阵的话,只会更加恐怖。(但是有方法)
区间估计和假设检验的R语言实现
虽然上面扯得看起来很复杂,但是到R语言实现的时候反而很简单。
我们只以单样本,方差未知时的均值t检验为例简介。因为真的简单到没边了。
只需要借助函数t.test即可。
先看帮助文档。

具体做起来,代码很简单。
|
|
啊,就没了。
t.test(x, y = NULL, alternative = c("two.sided", "less", "greater"), mu = 0, sigma.x = NULL, sigma.y = NULL, conf.level = 0.95, ...)
如果简单地说,t.test的语法是这样的。
这里:
x:第一个样本数据。y:第二个样本数据,如果是单样本t检验,则不需要提供。alternative:备择假设,可以是"two.sided"(双尾检验,默认值)、“less”(左尾检验)或"greater"(右尾检验)。mu:已知总体均值,默认为0。sigma.x和sigma.y:已知样本的标准差,如果未提供,则从数据中估计。conf.level:置信水平,默认为0.95。
当然,实际是t.test比这个强大多了,你想看全部的功能还是参考上面的文档吧。
我们运行一下,然后解析一下运行结果。
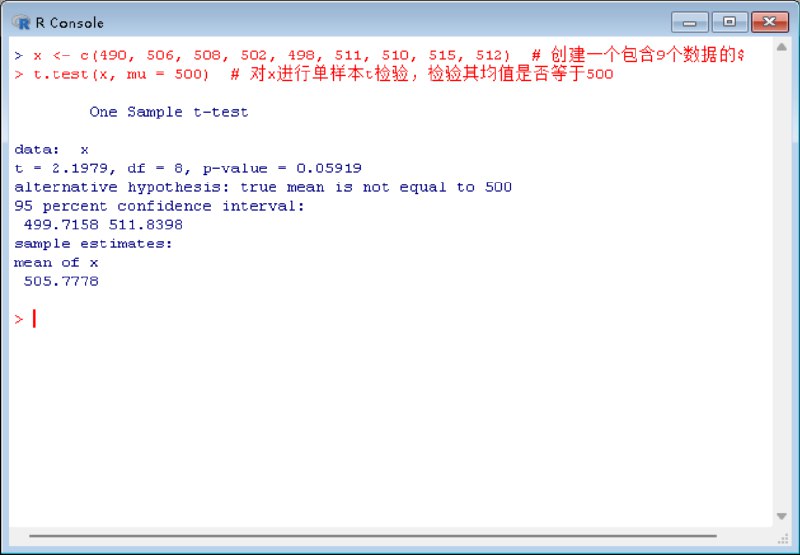
运行结果上看:
- One Sample t-test:表示进行的是单样本t检验。
- data: x:说明检验的数据是变量x。
- t = 2.1979:t检验的枢轴统计量值。
- df = 8:枢轴统计量的自由度。
- p-value = 0.05919:p值,用于判断统计显著性。通常,如果p值小于0.05,我们认为结果在统计上是显著的。
- alternative hypothesis: true mean is not equal to 500:备择假设,你只要翻译一下这句英文就可以了,这里是真实均值不等于500。
- 95 percent confidence interval::95%置信区间。
- 499.7158 511.8398:置信区间的具体范围。
- sample estimates::样本估计值。
- mean of x:x的样本均值。
- 505.7778:x的样本均值具体值。
从这里我们可以看到,t.test同时给出了假设检验需要的p-value和区间估计,所以这一个函数一次性就干了两件事,这也是为什么上一期我没有介绍区间估计的原因。
方差分析的R语言实现
如果要用R语言实现方差分析也很简单,核心是使用aov函数和gl函数。
gl函数是用来生成水平的,或者说生成数据。
gl函数的基本语法如下:
|
|
k:水平的数量,即因子的不同类别数。n:每个水平的重复次数。length.out:结果向量的长度,如果提供,则n会被忽略。labels:水平的标签,如果未提供,则默认为1到k的整数。ordered:逻辑值,指示生成的因子是否为有序因子,默认为FALSE。
gl函数返回一个因子向量,其中包含指定数量和重复次数的水平。
例如:
gl(3,4)表示有3个水平,每个水平出现4次,然后labels没输入所以是默认值,也就是1,2,3。
因此他会返回1111 2222 3333这样的因子向量。
而方差分析最核心的函数是aov。

aov的基本语法是
|
|
formula:是指定了模型的结构的公式。例如,y ~ A + B表示y是因变量,A和B是自变量(因素),如果要考虑交互作用的话可以写y~A*B或者y~A+B+A:Bdata:一个数据框,包含用于分析的数据。projections:逻辑值,指示是否计算投影矩阵。qr:逻辑值,指示是否使用QR分解。contrasts:一个列表,指定因素的水平对比方式。...:其他可选参数。
然后aov函数会返回一个对象里面包含结果,但是我们想查看的话通常要结束summary函数。
例如:
|
|
而summary后的报告也非常容易阅读,其实就是一元方差分析中介绍的方差统计表。
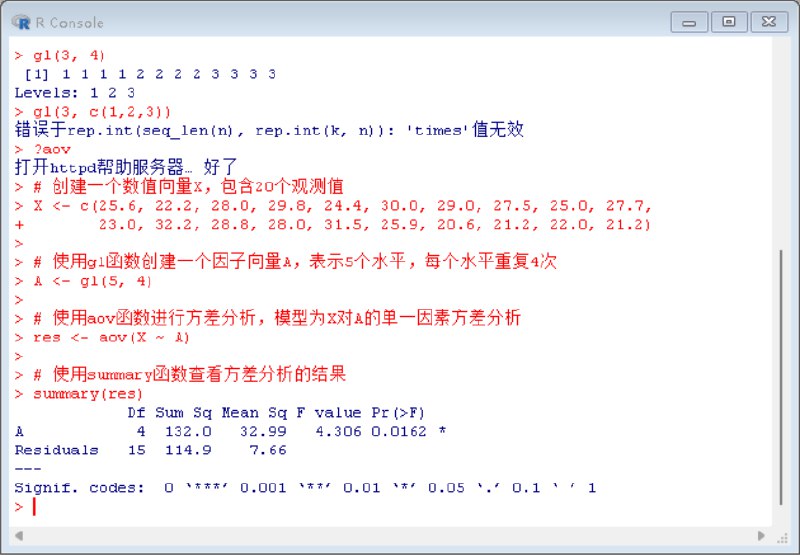
Df:自由度(Degrees of Freedom)A:因素A的自由度,为水平数减1,即5-1=4。Residuals:残差的自由度,为15。
Sum Sq:平方和(Sum of Squares)A:因素A的平方和,表示由于因素A的不同水平引起的变异。Residuals:残差的平方和,表示除因素A外其他因素引起的变异。
Mean Sq:均方(Mean Square)A:因素A的均方,为平方和除以自由度,即132.0/4=32.99。Residuals:残差的均方,为平方和除以自由度,即114.9/15=7.66。
F value:F值,为因素A的均方除以残差的均方,即32.99/7.66=4.306。F值用于检验因素A的显著性。Pr(>F):p值,表示在零假设(因素A对结果没有影响)为真时,观察到当前或更极端结果的概率。本例中p值为0.0162,小于0.05,表明因素A对结果有显著影响。
相关分析的R语言实现
这个话题本来不应该出现在这里的,但是这部分实在太短,没地方放。
在R语言中内置了很多相关系数,例如pearson、kendall、spearman相关系数(没错,统计学里其实有很多相关系数),他们都是用函数cor(x,y,method = "kendall")给出的。
这里x,y是待分析的两组数据,method=后面传的是具体的相关系数的名称。
至于相关分析的检验,其实和前面的没有任何区别,要借助cor.test函数。
|
|
你会得到这样的结果
|
|
Kendall's rank correlation tau:表示进行的是Kendall相关系数检验。data: x and y:说明检验的数据是变量x和y。T = 102:Kendall检验的T统计量值,它是用于计算相关系数的统计量。p-value = 1.016e-09:p值,如果这个p值小于0.05,表明x和y之间存在非常显著的相关性。alternative hypothesis: true tau is not equal to 0:备择假设,表示真实的Kendall相关系数(tau)不等于0,即x和y之间存在相关性。sample estimates::样本估计值。tau:Kendall相关系数的估计值,范围为-1到1。接近1或-1表示强相关性,接近0表示无相关性。本例中tau值为0.9428571,表明x和y之间存在很强的正相关性。
啊就这么索然无味。