上一次玩数值计算方法,唠到矩阵分解说唠不动了,换换口味。那这不就来了。
在小学初中高中乃至大学,概率统计都是有部分分量的。但是哪怕是大学考研的课程《概率论与数理统计》都鲜少涉及多元特别是二元以上的统计方法。
本系列就专门针对这种多元以上的情况进行分析。
第一个部分就是对《概率论与数理统计》的拓展,在这门课里最常见的统计方法就是参数估计以及各种假设检验,还有什么方差分析啊云云。
第一期就从参数估计开始。
那要唠参数估计的话首先就得有参数吧。
这个的话直接把一元的扩展出来就可以了。
多元统计的参量
在多元情况呢,随机变量的维数就不是简单的一维了,所以我们不能用数字来表示随机变量而是要把随机变量化为随机向量。
一般地,n维随机变量就要用一个n维向量表示即$X=\begin{pmatrix} x_1 \ x_2 \ …\x_n \end{pmatrix}$。
而我们对某一个随机向量进行m次观测后就会得到m个向量值,我们可以把他拼成一个n行m列的矩阵,称为样本的资料矩阵。
对于多元随机变量,我们还是用累计分布函数、密度函数等式子来表达其概率分布,并且也只是在定义上进行简单的推广。
例如,
对随机变量$X=\begin{pmatrix} x_1 \ x_2 \ …\x_n \end{pmatrix}$,他的累积分布函数就是$F(X)=P(\vec{x}\le X)$
而密度函数f(X)的定义只是把1维随机变量密度函数中的定积分变成n重积分而已。
而在二维随机变量的时候有所谓的边缘分布,在n维的情况也是一样的。
我们讨论多元统计,只需要着重于不同点就可以了,相同点只需要以此类推即可。
至于多元统计的参量,也还是什么均值啊,方差啊之类的。
对n维随机变量$X=\begin{pmatrix} x_1 \ x_2 \ …\x_n \end{pmatrix}$所谓的均值$E(X)=\begin{pmatrix} E(x_1) \ E(x_2) \ …\E(x_n) \end{pmatrix}$
方差啊什么的定义则完全没变,只是变成了矩阵运算。
$D(X)=E[(X-E(X))(X-E(X))^T]$
协方差
$cov(X)=E[(X-E(X))(Y-E(Y))^T]$
需要注意的是,现在方差与协方差是一个矩阵,并且实际上在这样的定义下,方差阵和协方差阵的(i,j)就是对应的一个或两个分量的方差/协方差。
性质的话,仍然和一维随机变量一致,但是要注意的是,现在要用对等的矩阵表达。
例如,期望的线性性质$E(AX+BY)=AE(X)+BE(Y)$
$cov(X,X)=D(X)$
$COV(AX,BY)=Acov(X,Y)B^T$
但是样本的期望阵有一个新的性质!
我们设$\mu=E(X),\Sigma=D(X)$而A是常数矩阵
则有$E(X^TAX)=tr(A\Sigma)+\mu^TA\mu$
这个性质因为是一维所不具备的所以需要特别注意。
他的证明倒是非常简单,在两边的x上加上然后减掉$\mu$就可以了。
$E(X^TAX)=E((X-\mu+\mu)^TA(X-\mu+\mu))$
然后展开里面的乘法。
原式$=E((X-\mu)^TA(X-\mu)+(X-\mu)^TA\mu+\mu^TA(X-\mu)+\mu^TA\mu)$
中间两项的和是0,而两边的就是结论了,这样就证完了。
有的时候啊,为了偷懒,我可能还是会用这里定义的$\Sigma$这一个符号来表示某一个变量的方差,用$\mu$来表示均值,需要注意。
有了协方差,我们知道,协方差矩阵可以看做内积结构,从而可以通过两个向量在协方差这个内积结构下定义(线性)相关系数。
但是对于多元的情况,我们是比较难写出计算相关系数的矩阵形式的。
但是我们仍然可以仿照前面的定义,要求变量X,Y相关系数矩阵R的(i,j)元是$X_i,Y_j$的相关系数,从而拼出一个相关系数矩阵。
虽然我们没有写出相关系数矩阵的矩阵表达,但这样的相关系数矩阵仍然具备一维相关系数的良好性质。
例如,一个经过标准化(减去均值向量再除以方差即乘以方差的逆)后的数据的协方差矩阵就是原数据的相关系数矩阵。
前面都是针对随机向量的统计量,那针对经过实验得到的样本,我们还是用同样的方法扩展样本的统计量。
比如样本的均值/方差/协方差/相关系数/离差矩阵等,他们的(i,j)元仍然是对应两个一元变量的均值/方差/协方差/相关系数/离差矩阵。
多元正态分布
有了这些统计量,接下来自然是介绍随机变量的分布。在这里,我们只取一个最典型的正态分布的多元情况。
至于一元的什么卡方分布啊、t分布啊之类的,你在后面就会知道他们的多元版本了。
这里介绍多元正态分布,只是因为只有多元正态分布的密度函数比较简洁,而且在后续也会使用到。
我们以均值向量为$\mu$,方差为$\sigma$的p维正态分布$N_p(\mu,\sigma)$为例,他的密度函数是
$$f(\vec x)=\frac{e^{-\frac{(x-\mu)^T\Sigma^{-1}(x-\mu)}{2}}}{{(2\pi)}^{\frac{p}{2}}|\Sigma|^\frac{1}{2}}$$注意:$|\Sigma|$中的两个竖线是行列式!!!
额,这已经是多元分布里密度函数比较简洁漂亮的了。。。。
并且多元正态分布的性质非常好,不仅延续了一元正态分布独立等价于不相关、线性变换后仍是正态分布等性质,并且多元正态分布的边缘分布以及条件分布都是多元正态分布。
而且你从多元正态分布里取任意几个分量,把他们拼成一个新的随机向量(这叫随机变量的剖分),他也是正态分布。
这里还要注意一下,既然多元正态分布经过线性变换后还是正态分布,那么正态分布的均值它不就是把原来的几个变换施以线性变换后得来的统计量吗?
所以如果X服从$N_p(\mu,\Sigma)$,则$E(X)$服从$N_p(\mu,\frac{1}{n}\Sigma)$。
更进一步,样本离差阵$S=\sum_{i=1}^n(X_i-E(X))(X_i-E(X))^T$里,括号里的$X_i-E(X)$就也服从正态分布,从而S就可以表达为$S=\sum_{i=1}^nZ_iZ_i^T$,其中Z服从正态分布。这式子你不觉得和卡方分布很像吗?我们如果将$ZZ^T$看做一种“Z的平方”,那这就是p维正态分布的平方和了。(数学上应该是倒过来,实际上一维情况下的所谓正态分布的平方和,应当是$ZZ^T$的特殊情况)
是的,1928年威沙特就提出了卡方分布的升级版——威沙特分布。
如果$X_{(a)}=(X_{a1},X_{a2},…,X_{ap})^T$服从$N_p(\mu_a,\Sigma)$且相互独立,那么由$X(a)$拼成的随机矩阵
$$W_{p\times p}=\sum_{a=1}^nX_{(a)}X_{(a)}^T$$就服从非中心威沙特分布$W_p(n,\Sigma,Z)$,其中$Z=\sum_{a=1}^n\mu_a\mu_a^T$,$\mu_a$被称为非中心参数。
特比的,当$\mu_a=0$时,这个非中心威沙特分布就退化成了中心威沙特分布,记作$W_p(n,\Sigma)$。
这个威沙特分布的密度函数非常“简洁”啊,我就不打了,打起来太麻烦了,反正你看了也记不住。
总之,这个威沙特分布是卡方分布在p维正态分布情况下的推广,所以他也兼容了卡方分布的性质,例如
威沙特分布的和还是威沙特分布,进一步威沙特分布的二次型还是威沙特分布。
当然,我们这里引入威沙特分布是为了给样本离差阵找个家,样本离差阵应当服从$W_p(n-1,\Sigma)$,至于这里自由度为什么是n-1我想一维情况就应该已经说过了才对。是因为离差阵里有均值,而由均值和n-1个$X_i$就能推出剩下的那一个$X_i$了。
另外,参考其他文献可以知道p维正态分布的均值和样本离差阵独立。
这些的证明都超级麻烦的,在这里就没法证明了。
如果你想要使用其他分布的密度函数等信息,其实没必要手算。
实际上,对于多元统计分析,由于我们的数据都是多元的而且多元分布的密度函数啊计算啊都比较复杂,所以我们其实也不会去手算这些东西的,他本来就应当使用计算机了。
在统计学里,常用的统计软件是SPSS和R以及Python。
SPSS使用非常简单,只需要点点点就可以了,我觉得没有太多的好说的地方。
Python的话,虽然现在也非常火热,但是讲的人很多不缺我一个。
R语言的话在统计上使用率其实不低,但是讲的人比较少,所以来唠唠这个吧,挑战一下。
R语言是一款专门为统计而生的软件或者也算是编程语言。
正因为他是为统计而生的,所以他内置了很多统计学需要使用的工具。
例如在我们这里,如果你想得到一个分布的密度函数(density function),累积分布函数(distribution function,抱歉这个我实在找不到p这个字母),随机( random )数,下$\alpha$分位数( quantile function ),只需要使用d/p/r/q+对应分布名称就可以得到了。
例如在R语言中使用?dnorm命令可以查看dnorm的帮助文档。

你将看到这四个函数。
d是密度函数的意思,p是累积分布函数,q是下$\alpha$分位点,r是随机数。而norm是正态分布的意思。
dnorm的第一个参数是密度函数的自变量,mean是正态分布的均值(默认为0),sd是标准差(默认为1),参数log或log.p是要不要给概率取对数的意思,默认是不取对数的。
pnorm是累积分布函数,第一个参数q是分布函数的自变量。lower.tail是指要不要“反转”。我们知道分布函数是从-∞积分到x,如果你把lower.tail改成FALSE(或者F),那R语言给你的分布函数就是从x积分到+∞。
qnorm其实是分位点,他的第一个参数p是自变量,lower.tail如果是默认的TRUE(或者T)那么R语言会给你下$\alpha$分位点,反之给你上$\alpha$分位点。
rnorm则是随机数,n表示你要几个随机数。
在R语言中内置了超级多分布,我随便举几个例子(并不完整,想看完整的请查阅文档)
| 分布名称 | R语言函数(密度函数) | R语言函数(分布函数) | R语言函数(分位数函数) | R语言函数(随机数生成) |
|---|---|---|---|---|
| 正态分布 | dnorm | pnorm | qnorm | rnorm |
| 二项分布 | dbinom | pbinom | qbinom | rbinom |
| 泊松分布 | dpois | ppois | qpois | rpois |
| 指数分布 | dexp | pexp | qexp | rexp |
| 卡方分布 | dchisq | pchisq | qchisq | rchisq |
| F分布 | df | pf | qf | rf |
| t分布 | dt | pt | qt | rt |
| Beta分布 | dbeta | pbeta | qbeta | rbeta |
| Gamma分布 | dgamma | pgamma | qgamma | rgamma |
| Weibull分布 | dweibull | pweibull | qweibull | rweibull |
| Logistic分布 | dlogis | plogis | qlogis | rlogis |
| 对数正态分布 | dlnorm | plnorm | qlnorm | rlnorm |
| 威沙特分布 | dwish | pwish | qwish | rwish |
但是对于某些分布,R语言可能确实没有自带的。
这时你可以通过命令install.packages(包名)安装第三方扩展库。
也可以自己书写或采样。
例如我曾经在B站介绍了逆变换采样法。网址:https://www.bilibili.com/opus/823005107895402761
今天多送你一个。
格式点离散化方法
通过格式点离散化方法利用随机变量的密度函数p(x)抽样。
方法非常简单,分为4步。
- 在密度函数p(x)的有效取值范围取N个等距节点
- 计算$p(x_i)$
- 正则化$p(x_i)$,即给每一个$p(x_i)$除以$\sum_{i=1}^np(x_i)$
- 将正则化后的函数看做离散型随机变量的分布律,再有放回地抽样n个数
这样得到的n个数就是n个服从概率密度为p(x)的随机数了。
我们以标准正态分布为例进行R语言实现。
|
|
我们来解析一下上面的代码。
其实也都加了注释了的。
在R语言中等号=和箭头<-都可以用来赋值。我们这里先把1000赋值给了N,然后seq(-5, 5, length.out = N)表示在-5到+5生成N个等距节点。
再用densities <- dnorm(nodes)生成节点处的密度函数取值。
sum(densities)计算了密度函数取值的和。
normalized_densities <- densities / sum(densities)就将正则化后的结果赋给了变量normalized_densities。
接下来我们看最重点的samples <- sample(nodes, n_samples, prob = normalized_densities, replace = TRUE)。
观察sample的文档。

可以看到,sample是用于采样的函数。
samples <- sample(nodes, n_samples, prob = normalized_densities, replace = TRUE)中nodes是从哪里采样,在格式点离散化方法中是从等距节点中采样。第二个参数n_samples是要取几个采样点。prob是各采样点出现的概率。replace=TRUE表示要进行有放回采样。
后面的代码只是绘图并且与R语言自带的rnorm进行比较罢了。
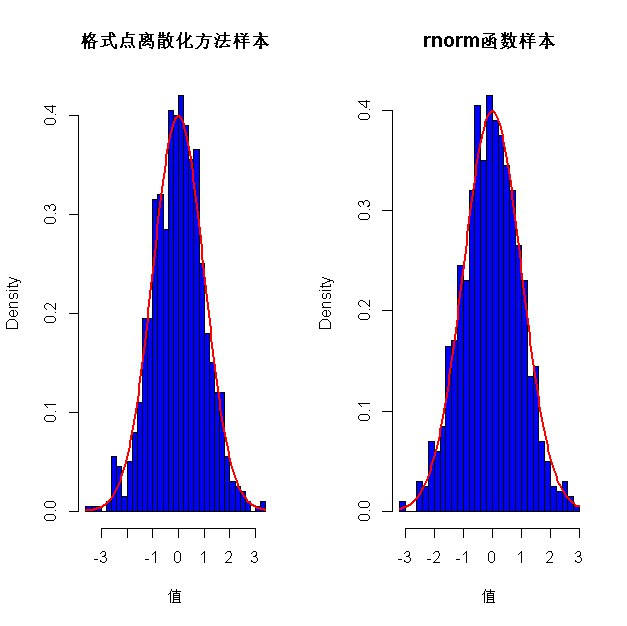
这是最后的绘图,可以看到我们用格式点离散化方法得到的随机数和R语言自带的rnorm非常接近,其频率直方图也和标准正态分布的密度函数(红线)很接近。
矩估计
好了好了,有了一个具体的分布,我们重要可以开始正题了。
还记得标题吗?
标题是参数估计。
我们从最简单的矩估计开始。
矩估计的统计依据是大数定律。
简单说就是样本的矩依概率收敛于样本的矩。
这么说肯定听不懂啊哈哈。
一个随机变量X的q阶矩,指的是$E(X^q)$。
而更多的时候我们会对随机变量进行中心化(也就是减去均值),从而得到中心矩$E((X-E(x))^q)$。
显然,随机变量的1阶矩就是均值,而2阶中心矩就是方差,这刚好就是他们的定义嘛。
所以我们最常用的就是这两个。
例如,你要估计样本均值为$\mu$,样本方差为S的p维正态分布的均值和方差,按照矩估计的原理直接就得到了,随机变量的均值=样本的均值=$\mu$,随机变量的方差=样本的二阶中心矩=样本的方差=S。
这就是矩估计了。
极大似然估计
下一个常见的估计方法是极大似然估计。
极大似然估计的统计思想是,一件事情如果发生了我应该往哪里估呢?应该往概率最大的地方估。
例如,X服从$N_p(\mu,\Sigma)$,你通过观测得到他的样本资料矩阵为X=($X_1$,$X_2$,…,$X_n$)。
那么为什么你观察到的资料阵是X呢?
因为这个事件(第一次观测$X=X_1$,然后$X=X_2,X=X_3,…$)出现的概率最大嘛。
而各个观测是独立的,所以上述事件发生的概率就是各概率的乘积即上述事件发生的概率是$L=\prod_{i=1}^nP(X=X_i)$。
那我们要估计的参数$\mu,\Sigma$就是使得L最大的参数。
在这里L被称为似然函数,但是实际上似然函数是一堆连乘处理起来很麻烦,所以我们常用的是对数似然函数,也就是两边取自然对数得到
$$\ln(L)=\sum_{i=1}^n\ln(P=(X=X_i))$$现在我们以多元正态分布$N_p(\mu,\Sigma)$进行演算。
先求似然函数,$L=\prod_{i=1}^nP(X=X_i)=\prod_{i=1}^n\frac{e^{-\frac{1}{2}(X_i-\mu)^T\Sigma^{-1}(X_i-\mu)}}{(2\pi)^{\frac{p}{2}}|\Sigma|^{\frac{1}{2}}}$
然后开始计算,分母都是常数,连乘n次就变成n次方。
分子是e指数,指数相乘底数不变指数相加。
$L=\frac{e^{-\frac{1}{2}\sum_{i=1}^n(X_i-\mu)^T\Sigma^{-1}(X_i-\mu)}}{(2\pi)^{\frac{np}{2}}|\Sigma|^{\frac{n}{2}}}$
然后计算对数似然函数$\ln(L)=-\frac{1}{2}\sum_{i=1}^n(X_i-\mu)^T\Sigma^{-1}(X_i-\mu)-\frac{np}{2}\ln(2\pi)-\frac{n}{2}\ln|\Sigma|$
接着只需要求参数$\mu,\Sigma$使得ln(L)最大就可以了。
那只需要验证KKT点即可,对于这种无约束极值就是找偏导数为0的点即驻点。
但是问题来了,这里的参数都是矩阵欸,你会对矩阵求导吗?
矩阵和向量的导数
所以现在还得倒过来补补基础了。
最基础的情况是一个多元函数对向量的导数。
然而,这里有两种写法。一种被称为分母布局,一种被称为分子布局,二者差一个转置。
对于多元函数$f(x_1,x_2,…,x_n)$和n维向量$X=(x_1,x_2,x_3,…,x_n)^T$,
分母布局的结果是$\frac{\partial f}{\partial X}=(\frac{\partial f}{\partial x_1},\frac{\partial f}{\partial x_2},\frac{\partial f}{\partial x_3},…,\frac{\partial f}{\partial x_n})^T$
这也就是所谓的f的梯度$\nabla f(X)$。
也就是多元函数的一阶导和梯度等同。
分子布局就是他的转置,以后我也不再说明,因为我都会使用分母布局。
而如果f也是一个向量,那情况会麻烦一些。
我们设$F=(f_1(X),f_2(X),…,f_m(X))^T=(f_1(x_1,x_2,…,x_n),f_2(x_1,…,x_n),…,f_m(x_1,…,x_n))^T$
那么理想的情况是:
$\frac{\partial F}{\partial X}=(\frac{\partial f_1}{\partial X},..,\frac{\partial f_n}{\partial X})^T$
然而,这时候$\frac{\partial f_1}{\partial X}$却是一个列向量,上面这玩意根本就不是个矩阵,炸裂!
所以这时候我们会再进行一个转置,即
$\frac{\partial F}{\partial X}=((\frac{\partial f_1}{\partial X})^T,..,(\frac{\partial f_n}{\partial X})^T)^T$
然后再写开,这样就得到了一个矩阵:
$\frac{\partial F}{\partial X} = \begin{pmatrix} \frac{\partial f_1}{\partial x_1} & \frac{\partial f_1}{\partial x_2} & \cdots & \frac{\partial f_1}{\partial x_n} \ \frac{\partial f_2}{\partial x_1} & \frac{\partial f_2}{\partial x_2} & \cdots & \frac{\partial f_2}{\partial x_n} \ \vdots & \vdots & \ddots & \vdots \ \frac{\partial f_m}{\partial x_1} & \frac{\partial f_m}{\partial x_2} & \cdots & \frac{\partial f_m}{\partial x_n} \end{pmatrix}$
而这个矩阵呢,有一个名字叫做雅可比矩阵,有时记作J。(注意,你看到的文献也许和这个差一个转置,这是因为他采用的是分子布局)
在多元统计的公式里,多元向量函数的一阶导和雅可比矩阵等同。
而与多元向量函数的二阶导等同的是黑塞矩阵,但是多元向量函数F(X)的黑塞矩阵是三维的$H = \begin{pmatrix} \frac{\partial^2 f_1}{\partial x_1^2} & \frac{\partial^2 f_1}{\partial x_1 \partial x_2} & \cdots & \frac{\partial^2 f_1}{\partial x_1 \partial x_n} \ \frac{\partial^2 f_1}{\partial x_2 \partial x_1} & \frac{\partial^2 f_1}{\partial x_2^2} & \cdots & \frac{\partial^2 f_1}{\partial x_2 \partial x_n} \ \vdots & \vdots & \ddots & \vdots \ \frac{\partial^2 f_1}{\partial x_n \partial x_1} & \frac{\partial^2 f_1}{\partial x_n \partial x_2} & \cdots & \frac{\partial^2 f_1}{\partial x_n^2} \end{pmatrix}, \begin{pmatrix} \frac{\partial^2 f_2}{\partial x_1^2} & \frac{\partial^2 f_2}{\partial x_1 \partial x_2} & \cdots & \frac{\partial^2 f_2}{\partial x_1 \partial x_n} \ \frac{\partial^2 f_2}{\partial x_2 \partial x_1} & \frac{\partial^2 f_2}{\partial x_2^2} & \cdots & \frac{\partial^2 f_2}{\partial x_2 \partial x_n} \ \vdots & \vdots & \ddots & \vdots \ \frac{\partial^2 f_2}{\partial x_n \partial x_1} & \frac{\partial^2 f_2}{\partial x_n \partial x_2} & \cdots & \frac{\partial^2 f_2}{\partial x_n^2} \end{pmatrix}, \ldots, \begin{pmatrix} \frac{\partial^2 f_m}{\partial x_1^2} & \frac{\partial^2 f_m}{\partial x_1 \partial x_2} & \cdots & \frac{\partial^2 f_m}{\partial x_1 \partial x_n} \ \frac{\partial^2 f_m}{\partial x_2 \partial x_1} & \frac{\partial^2 f_m}{\partial x_2^2} & \cdots & \frac{\partial^2 f_m}{\partial x_2 \partial x_n} \ \vdots & \vdots & \ddots & \vdots \ \frac{\partial^2 f_m}{\partial x_n \partial x_1} & \frac{\partial^2 f_m}{\partial x_n \partial x_2} & \cdots & \frac{\partial^2 f_m}{\partial x_n^2} \end{pmatrix}$
非常炸裂。
所以你只需要知道普通的多元函数f(X)的黑塞矩阵就可以了。
$H = \begin{pmatrix} \frac{\partial^2 f}{\partial x_1^2} & \frac{\partial^2 f}{\partial x_1 \partial x_2} & \cdots & \frac{\partial^2 f}{\partial x_1 \partial x_n} \ \frac{\partial^2 f}{\partial x_2 \partial x_1} & \frac{\partial^2 f}{\partial x_2^2} & \cdots & \frac{\partial^2 f}{\partial x_2 \partial x_n} \ \vdots & \vdots & \ddots & \vdots \ \frac{\partial^2 f}{\partial x_n \partial x_1} & \frac{\partial^2 f}{\partial x_n \partial x_2} & \cdots & \frac{\partial^2 f}{\partial x_n^2} \end{pmatrix}$
H的(i,j)元就是对应的二阶混合偏导嘛,也不难的。
我们也可以来推导看看,他为什么和f(X)的二阶导等同。
我们设$f=f(X)=f(x_1,x_2,…,x_n)$
那么,前面我们说过:
$\frac{\partial f}{\partial X}=(\frac{\partial f}{\partial x_1},\frac{\partial f}{\partial x_2},\frac{\partial f}{\partial x_3},…,\frac{\partial f}{\partial x_n})^T$这是一个列向量。
接着我们再进行一次求导,这就是对列向量进行求导,得到:
$\frac{\partial ^2f}{\partial X^2}=(\frac{\partial }{\partial X}(\frac{\partial f}{\partial x_1})^T,..,\frac{\partial f_n}{\partial X}(\frac{\partial f}{\partial x_n})^T)^T$
也就是
$\begin{pmatrix} \frac{\partial^2 f}{\partial x_1^2} & \frac{\partial^2 f}{\partial x_1 \partial x_2} & \cdots & \frac{\partial^2 f}{\partial x_1 \partial x_n} \ \frac{\partial^2 f}{\partial x_2 \partial x_1} & \frac{\partial^2 f}{\partial x_2^2} & \cdots & \frac{\partial^2 f}{\partial x_2 \partial x_n} \ \vdots & \vdots & \ddots & \vdots \ \frac{\partial^2 f}{\partial x_n \partial x_1} & \frac{\partial^2 f}{\partial x_n \partial x_2} & \cdots & \frac{\partial^2 f}{\partial x_n^2} \end{pmatrix}=H$
所以
$\frac{\partial ^2f}{\partial X^2}=\begin{pmatrix} \frac{\partial^2 f}{\partial x_1^2} & \frac{\partial^2 f}{\partial x_1 \partial x_2} & \cdots & \frac{\partial^2 f}{\partial x_1 \partial x_n} \ \frac{\partial^2 f}{\partial x_2 \partial x_1} & \frac{\partial^2 f}{\partial x_2^2} & \cdots & \frac{\partial^2 f}{\partial x_2 \partial x_n} \ \vdots & \vdots & \ddots & \vdots \ \frac{\partial^2 f}{\partial x_n \partial x_1} & \frac{\partial^2 f}{\partial x_n \partial x_2} & \cdots & \frac{\partial^2 f}{\partial x_n^2} \end{pmatrix}=H$
这也是为什么我们说,对普通的一元函数来说,它的黑塞矩阵和二阶导等同。
如果接下来,你要对f求三阶导,那就是对黑塞矩阵求导,自然你会得到一个三维矩阵,也非常炸裂,就不多说了。
雅可比矩阵和黑塞矩阵在这个系列中只会出现在理论推导里,而实际运算的时候不会涉及到。
在实际计算的时候我们更多地会遇见下面几个公式,可以自己用上面的定义推导一下,都不难。
$\frac{\partial (AX)}{\partial X}=A^T$(如果是分子布局则不用转置)
$\frac{X^TAX}{\partial X}=AX+A^TX$,特别的当A为对称阵的时候我们知道$X^TAX$为二次型,此时$\frac{X^TAX}{\partial X}=AX+A^TX=2AX$
$\frac{\partial (X^TAX)}{\partial A}=X^TX$
$\frac{\ln|A|}{\partial A}=A^{-1}$
至于求导法则,都是兼容的。
但是有一个要注意的,就是链式法则。
在一元情况下我们说$\frac{dy}{dx}=\frac{dy}{du}\frac{du}{dx}$,这个式子看着特别漂亮,似乎可以把du约掉一样,但是在多元的时候情况就不一样了。
$\frac{\partial y}{\partial x}=\frac{\partial u}{\partial x}\frac{\partial y}{\partial u}$
这看起来只是把式子右边两个导数换了一下位置,其实不是这样的。
在多元情况下,你也看到了,求导的结果是一个矩阵,矩阵乘法是不满足交换律的。实际上链式法则就应该是我们下面给出的这个形式而不是一元的那个漂亮的形式。那个形式反而是用一元情况下数的交换律交换出来的。这也是为什么前面反复强调,求导这里你不能把$\frac{dy}{dx}$简单地看做微分dy除以微分dx,这只是形式上的结果而已。同样你也不能认为链式法则里我们只是在分式上约掉了du,这也只是一元链式法则在形式上的结果而已。
多元正态分布的极大似然估计
好了,现在我们继续推导多元正态分布的极大似然估计吧。
前面我们已经推导到,多元正态分布的极大似然估计只需要找到$\mu,\Sigma$使得下面这个对数似然函数最大即可。
$\ln(L)=-\frac{1}{2}\sum_{i=1}^n(X_i-\mu)^T\Sigma^{-1}(X_i-\mu)-\frac{np}{2}\ln(2\pi)-\frac{n}{2}\ln|\Sigma|$
那么我们要做的是求对数似然函数的驻点,就是要解方程$\frac{\partial \ln(L)}{\partial \mu}=0$和$\frac{\partial \ln(L)}{\partial \Sigma}=0$
我们先来算$\frac{\partial \ln(L)}{\partial \mu}$,和$\mu$有关的只有$-\frac{1}{2}\sum_{i=1}^n(X_i-\mu)^T\Sigma^{-1}(X_i-\mu)$这一项,而这一项里求和号可以和求导交换位置,求和号内部则是一个二次型的导数,利用前面的公式$\frac{X^TAX}{\partial X}=AX+A^TX=2AX$即可。
所以$\frac{\partial \ln(L)}{\partial \mu}=-\frac{\partial \ln(L)}{\partial (X_i-\mu)}=\sum_{i=1}^n\Sigma^{-1}(X_i-\mu)=0$
同理$\frac{\partial \ln(L)}{\partial \Sigma}=\frac{1}{2}\sum_{i=1}^n(X_i-\mu)(X_i-\mu)^T(\Sigma^{-1})^2-\frac{n}{2}\Sigma^{-1}=0$
然后解方程就可以了,解得$\mu=\frac{1}{n}\sum_{i=1}^nX_i=E(X),\Sigma=\frac{1}{n}\sum_{i=1}^n(X_i-E(X))(X_i-E(X))^T=\frac{1}{n}S$
上面的解里,第一个等式是直接求解的结果,第二个等式则是将结果用我们前面说的样本的统计量替换了。
我们可以看到,多元正态分布均值的极大似然估计就是样本均值向量,而方差则是$\frac{1}{n}$乘以样本离差阵。
需要注意的是,我们前面定义的样本协方差阵是$\frac{1}{n-1}S$而不是这里的$\frac{1}{n}S$(当然也有教材直接把$\frac{1}{n}$定义为样本协方差阵的)。
但是我们更要注意的是,只有$\frac{1}{n-1}S$才是方差的无偏估计,这里我们用极大似然估计推导出来的$\frac{1}{n}S$只是方差的一致估计(即当n趋于无穷大时结果和无偏估计一致)。
牛顿法求数值解
在上面的过程中我们可以看到,无论是用矩估计还是极大似然估计,其核心都是求解方程组,然而大多数多元分布的密度函数都超级复杂,从而你根本解不动方程。我们在上个系列(数值计算方法中)已经介绍过如何用迭代法求解一维非线性方程组的数值解了,在这里简单地推广一下。
一维情况下方程f(x)=0有牛顿迭代格式$x_{k+1}=x_k-\frac{f(x_k)}{f’(x_k)}$,而到了多元情况我们会得到n个方程即
$f_1(X)=0,f_2(X)=0,…,f_n(X)=0$
我们知道,可以用同一个向量$F(X)=0$表达,这时的情况就和一元的f(x)=0在形式上差不多了。
迭代格式的话也是一样的,也就是直观上不严谨地说$X_{k+1}=X_k-\frac{F(X_k)}{F’(X_k)}$。
但是前面我们已经说过,对向量函数对另一个向量X的所谓导数$\frac{\partial F}{\partial X} = \begin{pmatrix} \frac{\partial f_1}{\partial x_1} & \frac{\partial f_1}{\partial x_2} & \cdots & \frac{\partial f_1}{\partial x_n} \ \frac{\partial f_2}{\partial x_1} & \frac{\partial f_2}{\partial x_2} & \cdots & \frac{\partial f_2}{\partial x_n} \ \vdots & \vdots & \ddots & \vdots \ \frac{\partial f_m}{\partial x_1} & \frac{\partial f_m}{\partial x_2} & \cdots & \frac{\partial f_m}{\partial x_n} \end{pmatrix}$是雅可比矩阵J(X)。
那么就炸裂了,式子里所谓的除以F(X)的“导数”到底是左乘J的逆还是右乘?
答案是左乘。
$X_{k+1}=X_{k}-J^{-1}(X_k)F(X_k)$
而如果是极大似然估计,我们最终是要求导函数的零点,也就是F(X)本身就是一阶导了,那么再代入迭代格式就是要用所谓的一阶导替代f(x)用所谓的二阶导替代f’(x)。
我们知道,一元情况的一阶导和雅可比矩阵等同,一元情况的二阶导和黑塞矩阵等同。
所以如果我想直接用牛顿法求普通的多元函数f(X)的极值点的话,前面我们说过对多元函数f(X)和一阶导等同的是梯度$\nabla f(X)$,和二阶导等同的是黑塞矩阵H(X)。
从而求普通多元函数f(X)的极值点,就是解方程$\nabla f(X)=0$
再用牛顿法求数值解就得用迭代格式:
$X_{k+1}=X_k-H^{-1}(X_k)\nabla f(X)$
R语言实现
可以看到,无论是矩估计还是极大似然估计,其本身并没有难点,最后的落脚点都是如何求解一个非线性方程的数值解。
这时候你可以MATLAB启动,也可以继续用R语言。
$$ \begin{cases} x_1^2 + x_2^2 - 5 = 0, \\ (x_1 + 1)x_2 - (3x_1 + 1) = 0. \end{cases} $$要用牛顿迭代法实现,就得先求其一阶导也就是雅可比矩阵。
$$J(x) = \begin{pmatrix} 2x_1 & 2x_2 \\ x_2 - 3 & x_1 + 1 \end{pmatrix}$$然后就可以写代码了。
|
|
上面的代码注释已经很详细了。
你需要注意的是,在这里雅可比矩阵是我们手动求解的。
然后x <- x - solve(obj$J, obj$f),这里的solve函数其实是用来解线性方程组AX=B的。
我们知道AX=B的解就是$A^{-1}B$,所以这里可以用solve来求$J^{-1}F$。
norm(x1 - x, "2")这里的norm用于求解矩阵或向量的范数,后面的2表明求解的是2-范数。范数的概念已经在上一个系列(数值计算方法)说明了,这里就不再废话了。
虽然用上面的方法可以求解非线性方程组的根,但是每次都这么计算一通非常麻烦。
我们可以调用R语言自带的包直接求解。
针对一元非线性方程,直接使用uniroot函数即可求解。
|
|
运行结果的话是这样的。
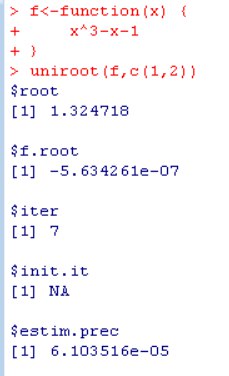
这里函数f是$x^3-x-1$,就表明我们要求解$x^3-x-1=0$的根。
我们向uniroot传入的第二个参数是零点可能存在的区间[1,2]。
然后我们得到的结果是一个列表,包含以下元素:
root: 这是函数f的根,即在区间[1, 2]内使得f(x) = 0的x值。在这个例子中,根的值是1.324718。f.root: 这是函数f在找到的根处的函数值。理论上,这个值应该接近于零,因为根就是函数值为零的点。在这个例子中,函数值是-5.634261e-07,这是一个非常接近于零的数,表明找到了一个很好的近似根。iter: 这是uniroot函数找到根所需的迭代次数。在这个例子中,进行了7次迭代。init.it: 这是初始迭代次数,但在您的结果中显示为NA,这可能是因为uniroot函数没有提供这个信息。estim.prec: 这是估计的精度,即函数值在根处的绝对误差的上界。在这个例子中,估计精度是6.103516e-05,这意味着函数值在根处的误差不会超过这个值。
总结来说,uniroot 函数在区间 [1, 2] 内找到了函数 f(x) = x^3 - x - 1 的一个根,大约在 x = 1.324718,并且在这个点处函数值非常接近于零,表明找到了一个有效的根。
(感谢智谱chatglm的回答,帮我省了几秒钟的打字时间,要是他能学会解数学题就好了啊哈哈,那我直接天天用ai发文啊哈哈哈哈哈哈哈)
如果你想求解多元非线性方程组,那只能借助第三方库了。
例如:
|
|
AI直接生成了这么完备的解释,我也只能闭嘴了。
但是我们其实还可以更懒。
上面的代码只对矩估计比较方便,但是对极大似然估计,我们还得自己来求解一阶导,非常麻烦。
所以我们应该直接使用R语言提供的优化问题的函数。
一元情况直接调用R语言提供的optimize函数,不过他默认求的是最小值。
|
|
如果是找普通的多元函数的极小值就可以借助nlm函数。
|
|
当然,你如果还是想用刚刚介绍的牛顿法手搓也是可以的。
第一步还是定义要求解的函数
|
|
然后参考迭代格式:
$X_{k+1}=X_k-H^{-1}(X_k)\nabla f(X)$
我们得先求f的梯度,你可以自己手动求解,也可以用我们在前一个系列数值计算方法里的数值微分方法求解。
我们这里就用最简单的差分法求解了。
|
|
同样地,你也可以使用第三方库直接计算梯度和黑塞矩阵。
|
|
这些代码还是比较简单的。
我们这里给一个利用numDeriv包求解梯度和黑塞矩阵再用牛顿法求解的代码。
|
|